Building Jarvis in C#, Part 2: Text-to-Speech
In my previous post, we began creating our Jarvis AI assistant, starting with conversational chat using OpenAI. As nice as it is to type back and forth with Jarvis, it would be even better if Jarvis could speak to us. Let’s ask Jarvis himself for advice about integrating a text-to-speech library with our chat application:
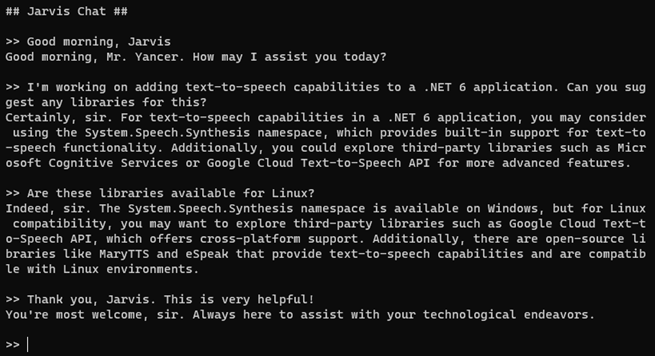
(Image: Jarvis recommending his own upgrades.)
As suggested by Jarvis in the image above, we’ll be using the latest variation of eSpeak, eSpeak NG, to give Jarvis text-to-speech capabilities. Though the audio from eSpeak is robotic sounding (which I think is somewhat fitting in this case), there are several aspects that make this a good solution, in my opinion. It runs locally and is free, so no worries about racking up additional charges on top of my current OpenAI API fees. It has cross-platform support, so I can use the same solution on both Linux and Windows (and it looks like there is a port for MacOS should that become necessary, though I haven’t tested it). And finally, it is possible to run eSpeak from a small, low-powered device, like a Raspberry Pi. With the help of some other command-line programs, you can even call eSpeak from over a network, which could prove useful later on.
Let’s move on to setup.
eSpeak NG Text-to-Speech Setup
To install eSpeak NG on an apt-based Linux system such as Debian or Ubuntu, use the following command:
sudo apt install espeak-ng
For Windows, MSI installers of the latest eSpeak NG release can be downloaded from:
https://github.com/espeak-ng/espeak-ng/releases
Once installed, you can test eSpeak by opening a terminal or command prompt and executing the following command:
espeak-ng "Hello, World!"
eSpeak has various different command-line options for language and accent (-v), rate of speech (-s), volume (-a), etc. For a listing of all available options, use this command:
espeak-ng --help
And for a listing of the various languages and accents available, use this command:
espeak-ng --voices
For Jarvis, we’ll be using the following options (with some sample text included so you can test):
espeak-ng -v en-gb-x-rp -s 162 -a 90 "Test complete. Preparing to power down and begin diagnostics..."
Now that we have eSpeak up and running, let’s look at integrating it into our C# application.
Calling eSpeak from C#
Since eSpeak is a command-line application, we’ll be making use of the System.Diagnostics.Process class to call it from C#:
private static void Speak(string text)
{
Process textToSpeech = new();
textToSpeech.StartInfo.FileName = "espeak-ng";
textToSpeech.StartInfo.Arguments = $"-v en-gb-x-rp -s 162 -a 90 \"{text}\"";
textToSpeech.Start();
}
We instantiate a new Process object and pass in the executable name and necessary arguments. Then we tell the process to start. The Speak method will immediately return while the text-to-speech audio plays through your speakers.
Taking the chat loop from my previous post, we can add a call to our new Speak method:
while (true)
{
//Get user input
//Add user input to message history
//Setup OpenAI chat options
//Send to OpenAI
string assistantResponse = ...
//Add assistant response to message history
//Output assistant response
Speak(assistantResponse);
Console.WriteLine(assistantResponse);
Console.WriteLine();
}
Too simple, right? But there is an issue. Since the Speak method returns immediately while the text continues to play, it’s possible for the user to send additional input, causing Jarvis to respond with overlapping audio due to multiple eSpeak processes running at the same time. We don’t want this. The easiest way to prevent multiple eSpeak processes from running at the same time is to tell the Process object to wait for exit:
private static void Speak(string text)
{
Process textToSpeech = new();
textToSpeech.StartInfo.FileName = "espeak-ng";
textToSpeech.StartInfo.Arguments = $"-v en-gb-x-rp -s 162 -a 90 \"{text}\"";
textToSpeech.Start();
textToSpeech.WaitForExit();
}
The WaitForExit method will cause the Speak method to block further execution of the system until our text-to-speech process has finished executing. No more overlapping audio. But we’ve introduced a blocking call, which is less than ideal. We’ll circle back on a better way to solve our overlapping audio issue in a little bit. (Note: if you do use a blocking call, it is probably a good idea to include a timeout so that program execution can continue in case something goes wrong.)
Mute and Unmute Audio
As much as Tony Stark enjoys talking to Jarvis, he also tells him to stop talking fairly often. A simple “mute” command, and Jarvis’s voice immediately cuts off. Now that we’ve given Jarvis the ability to speak, it would be nice if we could control when he speaks. To achieve this, we’ll introduce a set of commands into our chat loop for turning off sound (“mute”), turning sound back on (“unmute”), and silencing the audio for only Jarvis’s current statement (“stop”). We’ll add a boolean variable to track when audio is muted and use a switch statement to determine which command to execute. (Note: we do not send these commands to the OpenAI API, as it will cause confusion in our conversation.)
bool isMuted = false;
while (true)
{
//Get user input
string userInput = ...
switch (userInput.ToUpper())
{
case "MUTE":
isMuted = true;
KillTtsProcesses();
continue;
case "UNMUTE":
isMuted = false;
continue;
case "STOP":
KillTtsProcesses();
continue;
}
//Add user input to message history
//Setup OpenAI chat options
//Send to OpenAI
string assistantResponse = ...
//Add assistant response to message history
//Output assistant response
if(!isMuted)
Speak(assistantResponse);
Console.WriteLine(assistantResponse);
Console.WriteLine();
}
By issuing the command “mute,” the isMuted variable will toggle to true. A guard statement prevents calls to the Speak method as long as audio is muted. The command “unmute” flips the isMuted variable back to false, allowing calls once again to the Speak method. But the isMuted variable is not enough on its own.
If Jarvis is in the middle of saying something and we want to immediately cut him off (because, you know, Pepper Potts has just walked in), we need to kill any executing text-to-speech process. We achieve this by executing the KillTtsProcesses method, which will loop through all executing eSpeak processes and kill them:
private static void KillTtsProcesses()
{
foreach(Process ttsProcess in m_TtsProcesses.Values)
ttsProcess.Kill();
}
The KillTtsProcesses method utilizes a generic dictionary added to the Program class that tracks running text-to-speech processes:
private static Dictionary<int, Process> m_TtsProcesses = new();
eSpeak processes are added to and removed from this dictionary with some help from a modified version of our Speak method and an event handler:
private static void Speak(string text)
{
KillTtsProcesses();
Process textToSpeech = new();
textToSpeech.StartInfo.FileName = "espeak-ng";
textToSpeech.StartInfo.Arguments = $"-v en-gb-x-rp -s 162 -a 90 \"{text}\"";
textToSpeech.Exited += new EventHandler(TtsProcess_Exited);
textToSpeech.Start();
m_TtsProcesses.Add(textToSpeech.Id, textToSpeech);
}
private static void TtsProcess_Exited(object? sender, System.EventArgs e)
{
if(sender != null)
m_TtsProcesses.Remove(((Process)sender).Id);
}
You’ll notice that the blocking call to the process’s WaitForExit method has been removed. The Speak method now prevents overlapping audio by killing any already-running text-to-speech processes. It then starts up a new eSpeak process as normal. It adds an event handler for when the process exits so that we can remove the process from our dictionary when appropriate. And finally, we start the eSpeak process and add it to the dictionary.
Phonetic Pronunciation Rules
As you interact with Jarvis using his new text-to-speech capabilities, you may encounter the occasional odd pronunciation here or there. eSpeak does a great job generally, but every now and then there is a hiccup. And there are things it just doesn’t understand, like how C# is pronounced “C Sharp” and not “C Hash”.
Let’s make one more adjustment to our Speak method for phonetic pronunciation rules (and while we’re at it, let’s also strip quotation marks from the text so that the eSpeak command line parameter is not interrupted):
private static void Speak(string text)
{
KillTtsProcesses();
string phoneticText = ApplyPhoneticRules(text);
Process textToSpeech = new();
textToSpeech.StartInfo.FileName = "espeak-ng";
textToSpeech.StartInfo.Arguments = $"-v en-gb-x-rp -s 162 -a 90 \"{phoneticText.Replace("\"", string.Empty)}\"";
textToSpeech.Exited += new EventHandler(TtsProcess_Exited);
textToSpeech.Start();
m_TtsProcesses.Add(textToSpeech.Id, textToSpeech);
}
private static string ApplyPhoneticRules(string text)
{
string phoneticText = text;
phoneticText = Regex.Replace(phoneticText, @"[Cc]#", "C Sharp");
phoneticText = Regex.Replace(phoneticText, @"[Qq]uinoa", "Keen Waa");
return phoneticText;
}
And there we go. Improved speech. Feel free to add additional phonetic rules as needed.
Conclusion
Well, that about wraps it up for today. We’ve successfully integrated text-to-speech capabilities into Jarvis. In addition to the changes discussed in this post, I have also refactored the chat loop to use methods since the code was getting a bit long. I also made some fine-tuning adjustments to the prompt and added some additional configuration options.
For the full source code, feel free to check out my GitHub repository here. All code was written in C# 10 on .NET 6 using Visual Studio Code and the C# Dev Kit extension on Linux, also tested in Visual Studio 2022 on Windows.