Building Jarvis in C#, Part 5: Cross-Platform Audio
This post is a continuation of the Building Jarvis series.
As we continue our march towards adding speech-to-text capabilities to our Jarvis AI assistant, the next step is being able to record audio. After all, you can’t convert speech to text without first having the speech in your application. We’ll need to be able to interact with a microphone and control volume settings on the system. Let’s ask Jarvis for recommendations on microphone integration:
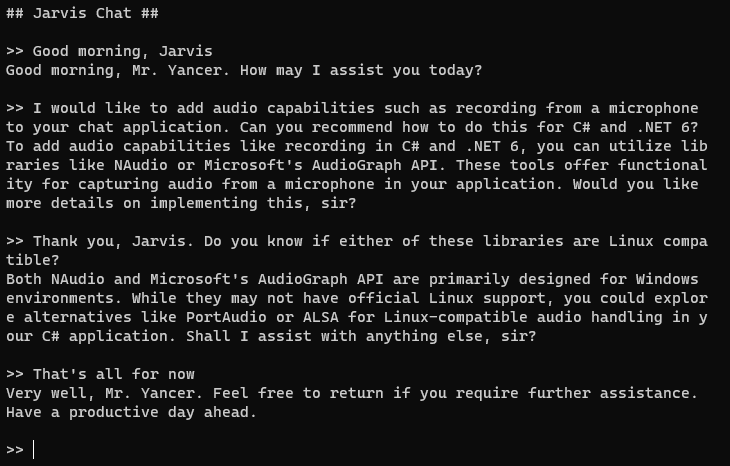
(Image: Jarvis recommending his own upgrades.)
It appears that we will likely not be able to use a single library for audio capabilities on both Windows and Linux. So how to proceed?
.NET has a strong built-in set of libraries. And with the advent of .NET Core, it’s amazing to see so many of them working equally well between Windows and Linux. But, inevitably, you’ll end up needing to do something that’s not covered by the base libraries. And here is where you run into a fundamental difference between the two platforms. The way you extend applications in Windows leans towards integrating with libraries. So you truck on over to NuGet and find what you need. But it will be hit or miss if these libaries work with Linux. If the library is pure logic or works with a REST API, there’s a good chance it will work. If instead it needs to interact with some hardware device or Windows API, you’re likely out of luck. So, what do you do? If you’re not able to find a Linux-compatible library, I’d like to suggest another approach. Adopt a Unix philosophy: 1) Everything is a file, and 2) extend apps by piping inputs and outputs between apps. So, on Linux, if you can’t find a suitable library, look for a console app that does what you want and then redirect standard input and standard output as needed to wire it up to your application. Suddenly, a world of possibility opens in front of you.
As Jarvis recommended above, we’ll be using the NAudio nuget package for the Windows side, and we’ll interact with ALSA on the Linux side using the amixer and arecord command line applications.
Windows Microphone
The NAudio NuGet package is available here. You can also add it to your project from the command line using the following command:
dotnet add package NAudio --version 2.2.1
With NAudio installed, we’ll be adding a Microphone class to our project. The first method will be responsible for starting microphone recording. Let’s take a look at that:
private const int RATE = 16000;
private const int CHANNELS = 1;
private readonly MemoryStream m_MicrophoneStream = new();
private WaveInEvent? m_Windows_WaveInEvent;
public void StartRecording()
{
if (OperatingSystem.IsWindows())
{
if (m_Windows_WaveInEvent == null)
{
m_Windows_WaveInEvent = new WaveInEvent()
{
DeviceNumber = 0,
WaveFormat = new WaveFormat(RATE, 16, CHANNELS),
BufferMilliseconds = 20
};
//use event to copy recording into memory until stopped
m_Windows_WaveInEvent.DataAvailable += (sender, e) =>
{
m_MicrophoneStream.Write(e.Buffer, 0, e.BytesRecorded);
};
}
try
{
m_Windows_WaveInEvent.StartRecording();
}
catch { } //No microphone
}
else
{
//Linux stuff for later
}
}
First, we need to initialize the WaveInEvent NAudio class if it hasn’t already been. This includes passing in the format of the audio. We then attach an event handler to the DataAvailable event to write microphone data into memory. Finally, WaveInEvent’s StartRecording method is used to turn the microphone on.
Now let’s look at how we stop recording and output the microphone data:
public byte[] StopRecording()
{
byte[] result = Array.Empty<byte>();
if (OperatingSystem.IsWindows())
{
if (m_Windows_WaveInEvent != null)
{
try
{
m_Windows_WaveInEvent.StopRecording();
}
catch { }
}
if ((m_MicrophoneStream != null) && (m_MicrophoneStream.Length > 0))
{
byte[] rawMicrophoneData = m_MicrophoneStream.ToArray();
m_MicrophoneStream.SetLength(0);
//convert raw microphone data to in-memory .wav file
using (MemoryStream memoryStream = new())
{
using (WaveFileWriter writer = new(memoryStream, new WaveFormat(RATE, 16, CHANNELS)))
{
writer.Write(rawMicrophoneData, 0, rawMicrophoneData.Length);
result = memoryStream.ToArray();
}
}
}
}
else
{
//Linux stuff for later
}
return result;
}
We make a call to the WaveInEvent’s StopRecording method to turn off the microphone. Then we check to see if there is any microphone data in the stream. If there is, we copy the microphone data into a byte array. We then have to reset the microphone stream back to 0 so that the next recording will not include audio we’ve already processed. NAudio records data in a raw format (despite all of the classes being called “Wave”), so we need to convert it into a .wav file format in memory so that when we return the byte array to the method caller, they will have the audio in a usable format. And that’s it. We’ve successfully recorded from the microphone in Windows.
Now let’s take a look at the Linux side.
Linux Microphone
To record audio from the microphone on Linux, we’ll be using the arecord command-line application. This should be included automatically in many Linux distributions. We’ll be calling arecord using the System.Diagnostics.Process class.
You may have noticed in the above methods that there were placeholders for Linux logic. Let’s take a look at those now. First up is the Linux implementation for StartRecording:
private const int RATE = 16000;
private const int CHANNELS = 1;
private readonly MemoryStream m_MicrophoneStream = new();
private Process? m_NonWindows_RecordingProcess;
private WaveInEvent? m_Windows_WaveInEvent;
public void StartRecording()
{
if (OperatingSystem.IsWindows())
{
//Windows stuff that we've already covered
}
else
{
//prep for new round of recording
if (m_NonWindows_RecordingProcess != null)
{
m_NonWindows_RecordingProcess.Dispose();
m_NonWindows_RecordingProcess = null;
}
//start speech recording
m_NonWindows_RecordingProcess = new();
m_NonWindows_RecordingProcess.StartInfo.FileName = "arecord";
m_NonWindows_RecordingProcess.StartInfo.Arguments = $"-f cd -r {RATE} -c {CHANNELS} -t wav -D default -q";
m_NonWindows_RecordingProcess.StartInfo.UseShellExecute = false;
m_NonWindows_RecordingProcess.StartInfo.RedirectStandardOutput = true;
m_NonWindows_RecordingProcess.StartInfo.RedirectStandardError = true;
//use separate thread to copy recording into memory until process is killed
Thread thread = new(() =>
{
byte[] buffer = new byte[1024];
int bytesRead;
while ((bytesRead = m_NonWindows_RecordingProcess.StandardOutput.BaseStream.Read(buffer, 0, buffer.Length)) > 0)
{
m_MicrophoneStream.Write(buffer, 0, bytesRead);
}
});
m_NonWindows_RecordingProcess.Start();
thread.Start();
}
}
First, we need to cleanup the existing Process if it’s not null. Then we establish a new instance of Process and configure the necessary settings to call the arecord command and pass in the necessary audio format details. Outputs are set to redirect so that we can gather the microphone data from standard output. We then create a thread that reads bytes from standard output and writes them into memory. With all of this in place, we are ready to start the process and the thread.
Now let’s look at how we stop recording and output the microphone data:
public byte[] StopRecording()
{
byte[] result = Array.Empty<byte>();
if (OperatingSystem.IsWindows())
{
//Windows stuff that we've already covered
}
else
{
if (m_NonWindows_RecordingProcess != null)
{
//stop recording
m_NonWindows_RecordingProcess.Kill();
if (m_MicrophoneStream != null)
{
//microphone data already in .wav file format
result = m_MicrophoneStream.ToArray();
m_MicrophoneStream.SetLength(0);
}
}
}
return result;
}
The StopRecording implementation for Linux is pretty simple. We kill the executing Process. This causes microphone data to cease writing into memory. We then copy the memory stream into our byte array and set the memory stream length to 0 so that the next recording will not include audio we’ve already processed. We now have microphone support in Linux.
Windows Sound Mixer
With microphone support available on both platforms, we now have what we need to record speech in our application. But perhaps a little too well. In my testing, I have found that if you use the push-to-talk feature while Jarvis is in the middle of speaking, he will record his own voice and then start talking to himself. It’s a little funny the first few times, but it also brings confusion into the conversation that prevents practical use. The solution I have settled on is to decrease system volume when the push-to-talk button is being held down and then restore the system volume when the push-to-talk button is released. To enable this, we’ll need to create a method for getting and setting volume. These methods will be added to a SoundMixer class. Let’s look at the Windows implementation for retrieving volume first:
public async Task<int> GetVolumeAsync()
{
int result = 100;
if (OperatingSystem.IsWindows())
{
using MMDeviceEnumerator enumerator = new();
using MMDevice device = enumerator.GetDefaultAudioEndpoint(DataFlow.Render, Role.Console);
float volume = device.AudioEndpointVolume.MasterVolumeLevelScalar;
result = (int)Math.Floor(volume * 100);
}
else
{
//Linux stuff for later
}
return result;
}
We’ll be making this method async due to the Linux implementation details, so ignore that part for now. First, we have NAudio give us an enumerator capable of retrieving the various devices in the system. We then get the default device. We retrieve the volume setting, which is a float between 0 and 1. We convert this into an int between 0 and 100 and return the result.
Now on to setting volume:
public void SetVolume(int volume)
{
if (OperatingSystem.IsWindows())
{
using MMDeviceEnumerator enumerator = new();
using MMDevice device = enumerator.GetDefaultAudioEndpoint(DataFlow.Render, Role.Console);
device.AudioEndpointVolume.MasterVolumeLevelScalar = volume / 100.0f;
}
else
{
//Linux stuff for later
}
}
Setting volume is similar to getting volume, but in the opposite direction. First, we have NAudio give us an enumerator to retrieve the audio devices in the system, and then we get the default device. Once we have it, we set the master volume level, making sure to convert our integer into a float between 0 and 1.
Now let’s look at filling in these Linux placeholders:
Linux Sound Mixer
We’ll be using the amixer command-line application to retrieve the current system volume. Similar techniques to what were used for arecord will be used again here; however, we’ll be reading textual data instead of audio data from the redirected output:
public async Task<int> GetVolumeAsync()
{
int result = 100;
if (OperatingSystem.IsWindows())
{
//Windows stuff that we've already covered
}
else
{
using (Process mixerProcess = new())
{
mixerProcess.StartInfo.FileName = "amixer";
mixerProcess.StartInfo.Arguments = $"-D pulse sget Master";
mixerProcess.StartInfo.UseShellExecute = false;
mixerProcess.StartInfo.RedirectStandardOutput = true;
mixerProcess.StartInfo.RedirectStandardError = true;
mixerProcess.EnableRaisingEvents = true;
TaskCompletionSource<string> tcs = new();
mixerProcess.Exited += (sender, e) =>
{
string output = mixerProcess.StandardOutput.ReadToEnd();
tcs.SetResult(output);
};
mixerProcess.Start();
await tcs.Task;
string output = tcs.Task.Result;
//find 1 to 3 digits with % enclosed in brackets
Regex regex = new(@"\[(\d{1,3})%\]");
Match match = regex.Match(output);
if (match.Success)
{
string volumeStr = match.Groups[1].Value;
bool success = int.TryParse(volumeStr, out int volume);
if (success)
result = volume;
}
}
}
return result;
}
We set up a Process class with amixer and the necessary arguments. Output is redirected so that we can read it with our application. We don’t know how long amixer will take to provide its output, so we obtain the output through an event handler attached to the Exited event on the Process. A TaskCompletionSource enables us to add await support to the event handler. Once we have the output, we use a regular expression to extract the volume percentage from the output string. If successful, we convert the string to an int and return it.
Setting the volume is much simpler:
public void SetVolume(int volume)
{
if (OperatingSystem.IsWindows())
{
//Windows stuff that we've already covered
}
else
{
using Process mixerProcess = new();
mixerProcess.StartInfo.FileName = "amixer";
mixerProcess.StartInfo.Arguments = $"-D pulse sset Master {volume}%";
mixerProcess.StartInfo.UseShellExecute = false;
mixerProcess.StartInfo.RedirectStandardOutput = true;
mixerProcess.StartInfo.RedirectStandardError = true;
mixerProcess.Start();
}
}
We use a Process to issue a call to amixer with the necessary arguments. We redirect output so that nothing appears on screen. And then we just start the Process. All done!
Conclusion
And that concludes this post. We have built cross-platform audio routines for Linux and Windows. The source code on GitHub also includes dispose handling. The next post will cover speech-to-text integration.
For Jarvis’s full source code, feel free to check out my GitHub repository here. All code was written in C# 10 on .NET 6. For this post, development was performed using Visual Studio Code and the C# Dev Kit extension on Linux and Visual Studio 2022 on Windows.